Webscraping with RSelenium
Automate your browser actions
LISER
February 22, 2023
Introduction
Do you really need scraping?
Before scraping: is there an API?
Introduction
Scraping can be divided in two steps:
- getting the HTML that contains the information
- cleaning the HTML to extract the information we want
These 2 steps don’t necessarily require the same tools, and shouldn’t be carried out at the same time.
Introduction
Why?
Webscraping takes time, and a lot of things can happen:
- your Internet connection goes down;
- the website goes down;
- any other random reason
If this happens and you didn’t save your progress, you lose everything.
We don’t have plenty of time, but we have plenty of disk storage. Use it!
Introduction
Here, we will focus mostly on how to obtain the HTML code you need on dynamic pages?
(And a bit on how to clean this HTML)
Static and dynamic pages
Static and dynamic pages
The web works with 3 languages:
- HTML: content and structure of the page
- CSS: style of the page
- JavaScript: interactions with the page
Static and dynamic pages
The web works with 3 languages:
HTML: content and structure of the page
CSS: style of the page
JavaScript: interactions with the page
Static vs dynamic
Static webpage:
- all the information is loaded with the page;
- changing a parameter modifies the URL
Dynamic webpage: the website uses JavaScript to fetch data from their server and dynamically update the page.
Example: Premier League stats.
Why is it harder to do webscraping with dynamic pages?
Webscraping a static website can be quite simple:
- you get a list of URLs;
- download the HTML for each of them;
- read and clean the HTML
and that’s it.
This is “easy” because you can identify two pages with different content just by looking at their URL.
Example: elections results in Spain from the website of El Pais
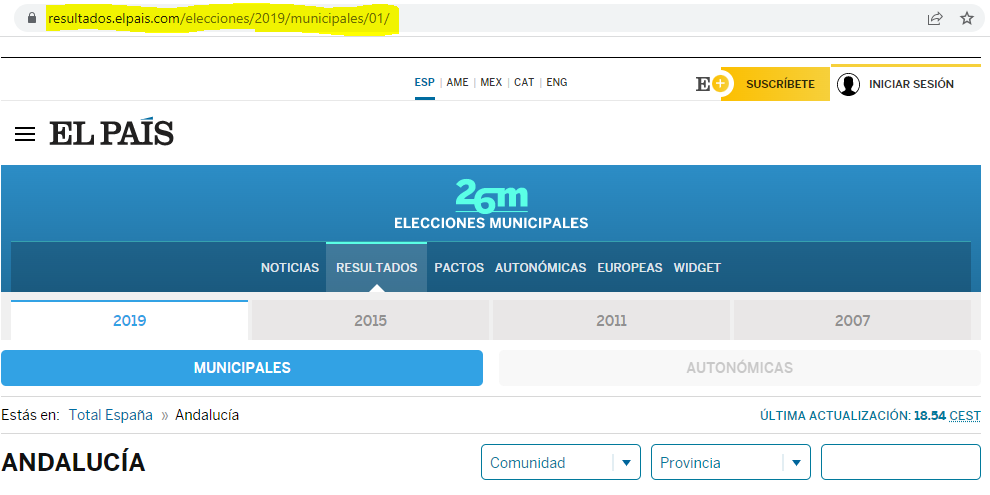
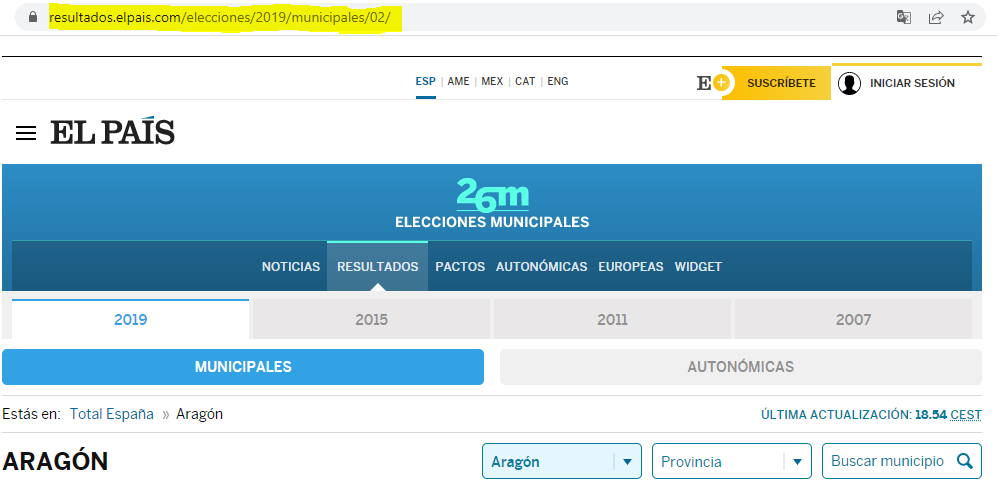
Of course, static webscraping can be challenging because we have to write good loops, good error handling, the HTML itself can be hard to clean, etc.
But in dynamic pages, there’s no obvious way to see that the inputs are different.
Example: Premier League stats
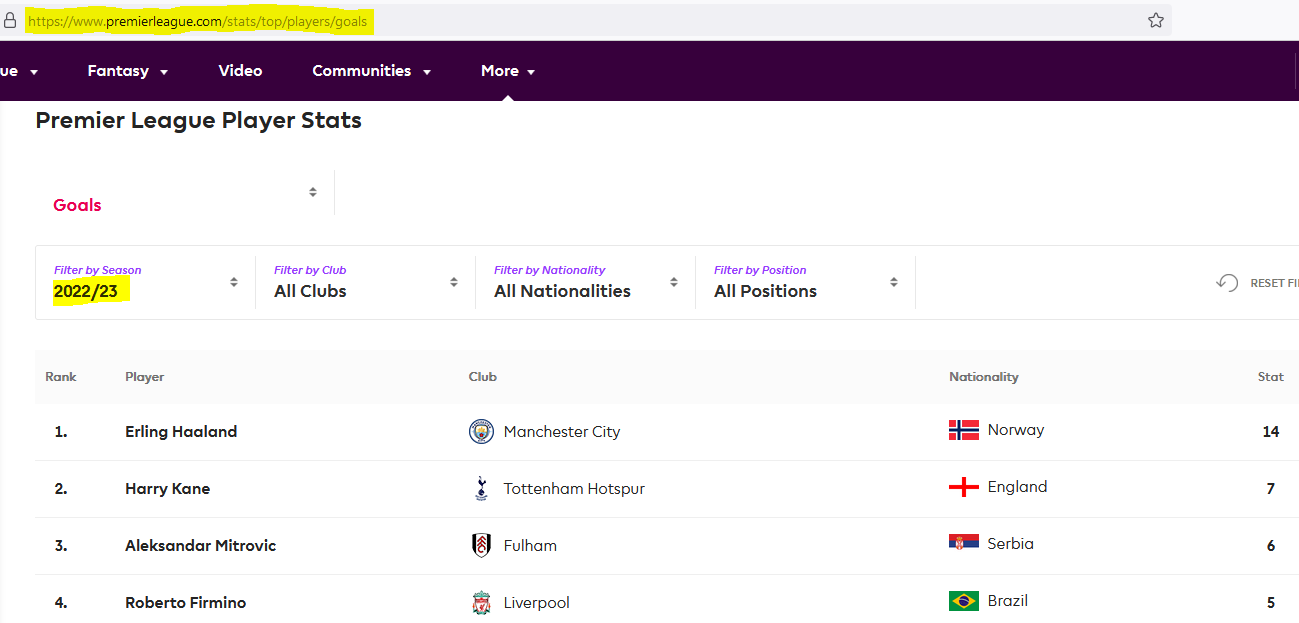
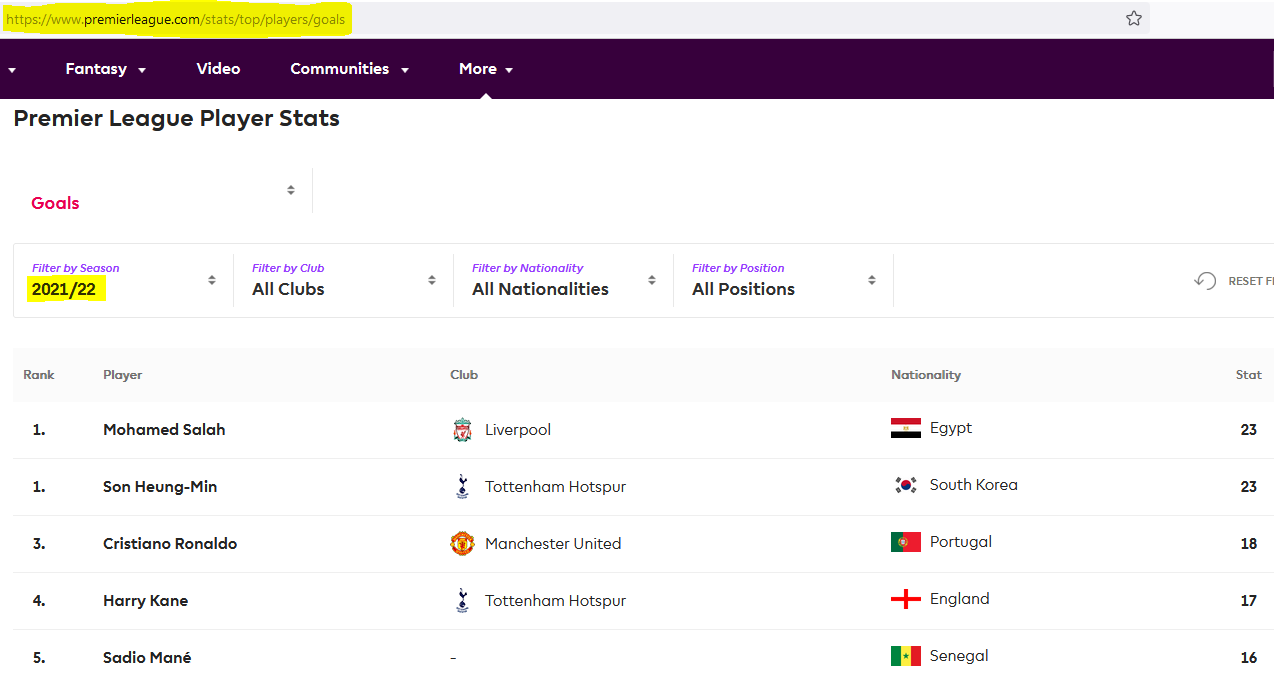
So it seems that the only way to get the data is to go manually through all pages to get the HTML.

(R)Selenium
Idea
Idea: control the browser from the command line.
“I wish I could click on this button to open a modal”
Almost everything you can do “by hand” in a browser, you can reproduce with Selenium:
| Action | Code |
|---|---|
| Open a browser | open() / navigate() |
| Click on something | clickElement() |
| Enter values | sendKeysToElement() |
| Go to previous/next page | goBack() / goForward() |
| Refresh the page | refresh() |
| Get all the HTML that is currently displayed |
getPageSource() |
Get started
Get started
In the beginning was the Word rsDriver():
If everything works fine, this will print a bunch of messages and open a “marionette browser”.

Installation issues
- Java not installed
If you have a message saying that “Java is not found” (or similar), you need to install Java:
- Windows search bar -> “Software Center”
- Install Java
Installation issues
- Firefox not installed/found
If you have a message saying “Could not open firefox browser”, two possible explanations:
if Firefox is not installed, install it the same way as Java on the previous slide.
if Firefox is installed but not found, it probably means that it wasn’t installed with admin rights, so you need to manually specify the location of the file:
Installation issues
- “Error in if (file.access(phantompath, 1) < 0) { : argument is of length zero”
If you have this error, this is bad news because I don’t really know how to fix it since I never had it.
You can try to follow this StackOverflow answer.
Get started
From now on, the main thing is to call <function>() starting with remote_driver$1.
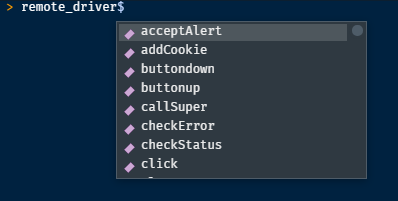
Closing Selenium
The clean way to close Selenium is to run driver$server$stop() (replace driver by the name you gave at the previous step).
If you close the browser by hand and try to re-run the script, you may have the following error:
"Error in wdman::selenium(port = port, verbose = verbose, version = version, :
Selenium server signals port = 4567 is already in use."To get rid of this error, you also need to run driver$server$stop().
Exercise 1
Exercise 1
Objective: get the list of core contributors to R located here.
How would you do it by hand?
- open the browser;
- go to https://r-project.org;
- in the left sidebar, click on the link “Contributors”;
and voilà!
How can we do these steps programmatically?
Open the browser and navigate
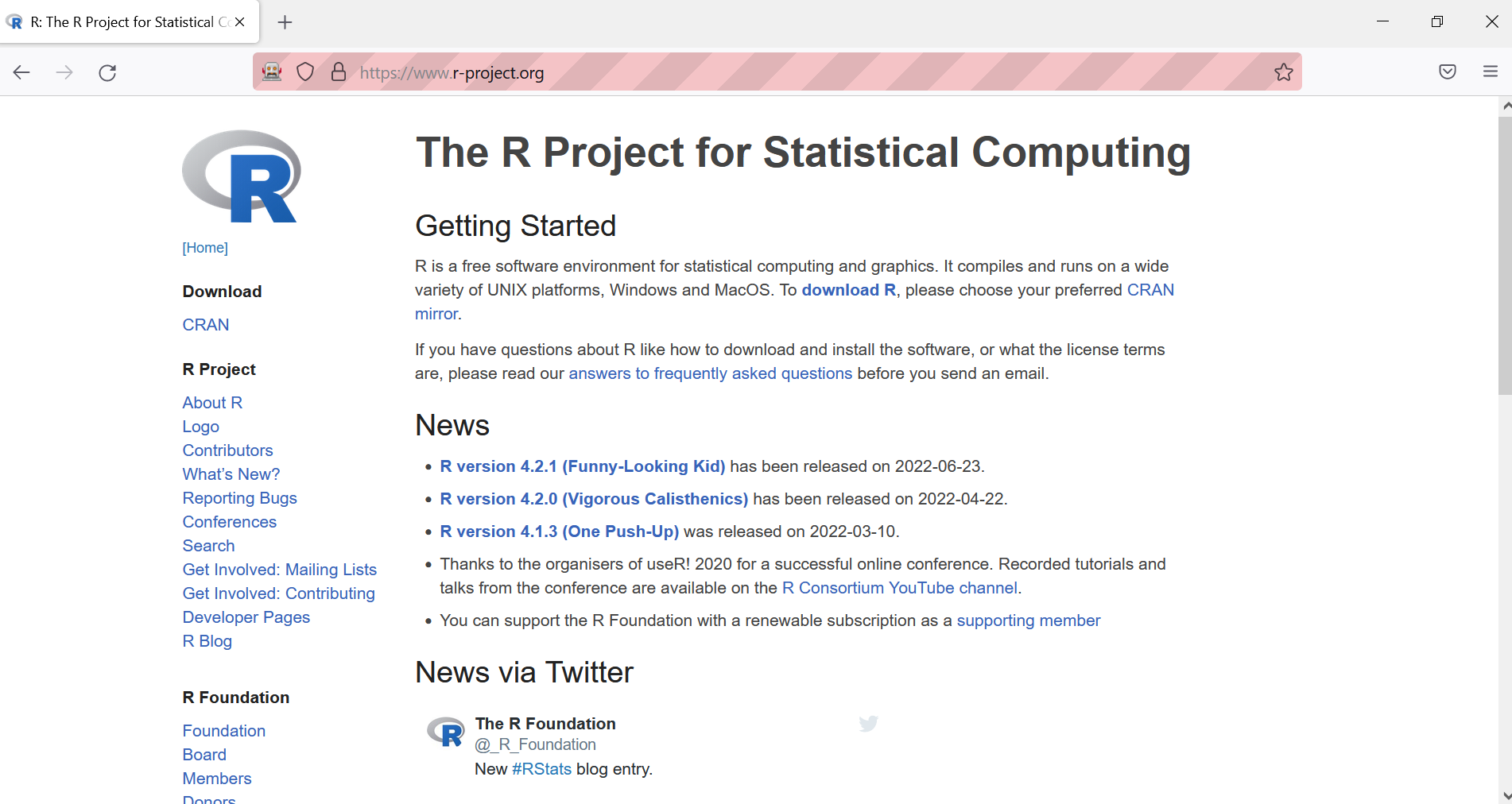
Click on “Contributors”
This requires two things:
- find the element
- click on it
How to find an element?
Humans -> eyes
Computers -> HTML/CSS
To find the element, we need to open the console to see the structure of the page:
- right-click -> “Inspect”
- or
Ctrl+Shift+C
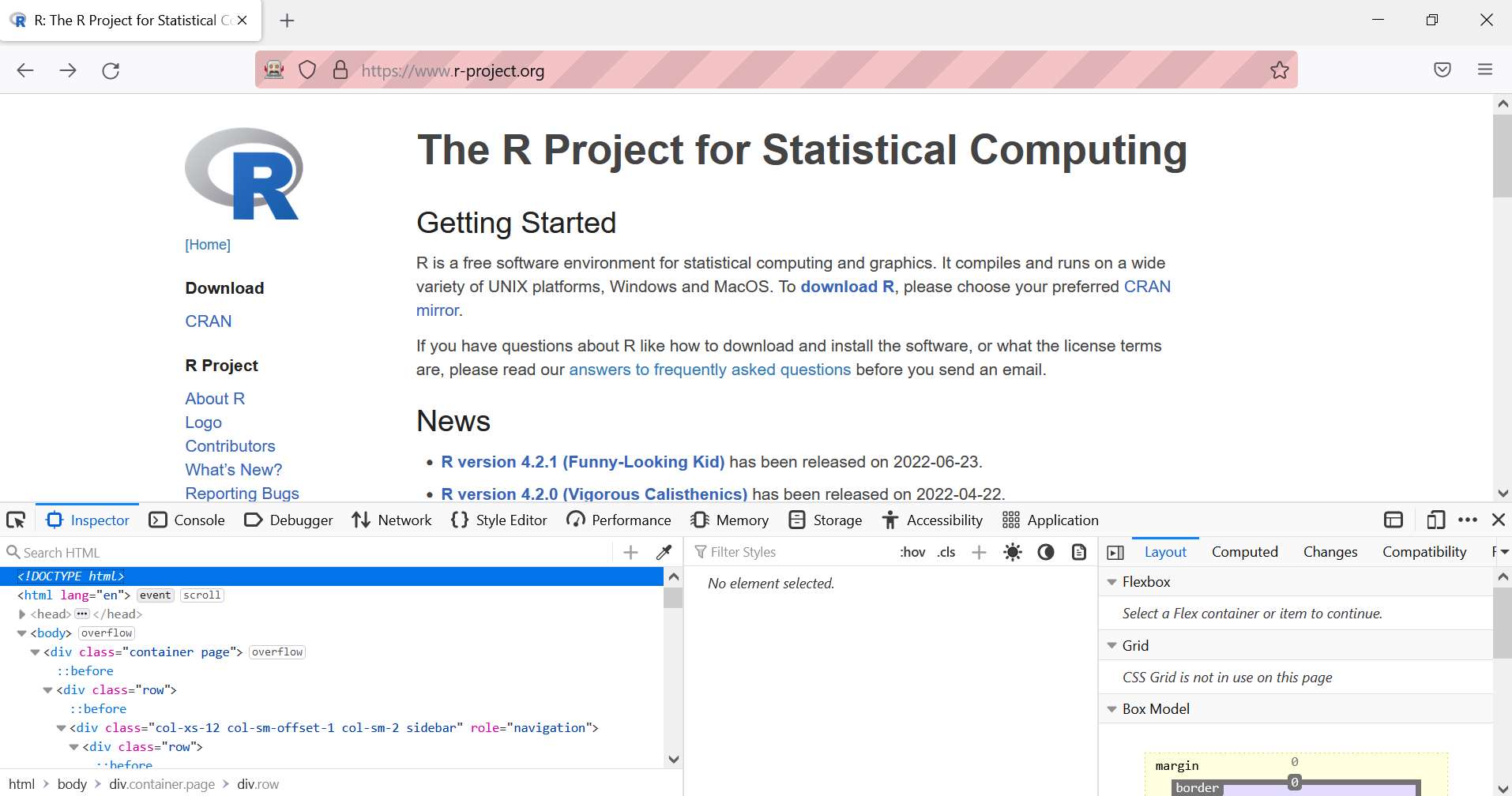
Then, hover the element we’re interested in: the link “Contributors”.
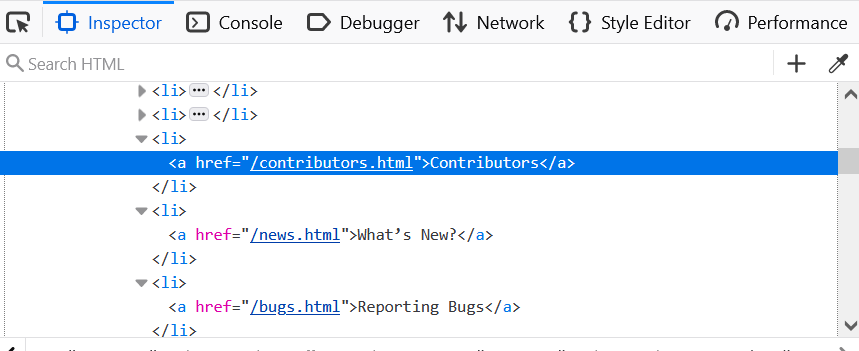
How can we find this link with RSelenium?
-> findElement
- class name ❌
- id ❌
- name ❌
- tag name ❌
- css selector ✔️
- link text ✔️
- partial link text ✔️
- xpath ✔️
We must make a distinction between two classes of objects: remoteDriver and webElement.
Think of remoteDriver as the browser in general: you can navigate between pages, search elements, find if an element is present on the page, etc.
see the list of available methods with ?remoteDriver
Think of webElement as a particular element on the page: you can highlight it, click it, get its text, etc.
see the list of available methods with ?webElement
Tip: You can check that you found the right element by highlighting it with highlightElement().
All of these work:
remote_driver$
findElement("link text", "Contributors")$
clickElement()
remote_driver$
findElement("partial link text", "Contributors")$
clickElement()
remote_driver$
findElement("xpath", "/html/body/div/div[1]/div[1]/div/div[1]/ul/li[3]/a")$
clickElement()
remote_driver$
findElement("css selector", "div.col-xs-6:nth-child(1) > ul:nth-child(6) > li:nth-child(3) > a:nth-child(1)")$
clickElement()We are now on the right page!

Last step: obtain the HTML of the page.
Do we read the HTML and extract the information in the same script?
Do we read the HTML code and extract the information in the same script?
No!
Instead, we save the HTML in an external file, and we will be able to access it in another script (and offline) to manipulate it as we want.
Click here to see the results.
Exercise 2: a harder & real-life example
The previous example was not a dynamic page: we could have used the link to the page and apply webscraping methods for static webpages.
Let’s now dive into a more complex example, where RSelenium is the only way to obtain the data.
Before using RSelenium
Using Selenium is slower than using “classic” scraping methods, so it’s important to check all possibilities before using it.
Use Selenium if:
the HTML you want is not directly accessible, i.e needs some interactions (clicking on a button, connect to a website…),
the URL doesn’t change with the inputs,
you can’t access the data directly in the “network” tab of the console and you can’t reproduce the
POSTrequest.
Example: Sao Paulo immigration museum
Steps:
- list all interactions we need to do
- check that we need Selenium
- make an example
- generalize and polish the code
List all interactions
- Open the website
- Enter “PORTUGUESA” in the input box
- Wait a bit for the page to load
- Open every modal “Ver Mais”
Check that we need Selenium
- Is there an API?
Not that I know of (and let’s assume that there isn’t one).
- Does the URL change when we enter inputs or click somewhere?
No.
- Can we get the data through the “Network” tab?
Yes but we still need RSelenium to change pages (and this is just training anyway).
Make an example
Initiate the remote driver and go to the website:
Make an example
Fill the field “NACIONALIDADE”:
library(RSelenium)
link <- "http://www.inci.org.br/acervodigital/livros.php"
# Automatically go the website
driver <- rsDriver(browser = c("firefox"))
remote_driver <- driver[["client"]]
remote_driver$navigate(link)
# Fill the nationality field and click on "Validate"
remote_driver$
findElement(using = "id", value = "nacionalidade")$
sendKeysToElement(list("PORTUGUESA"))Make an example
Find the button “Pesquisar” and click it:
library(RSelenium)
link <- "http://www.inci.org.br/acervodigital/livros.php"
# Automatically go the website
driver <- rsDriver(browser = c("firefox"))
remote_driver <- driver[["client"]]
remote_driver$navigate(link)
# Fill the nationality field and click on "Validate"
remote_driver$
findElement(using = "id", value = "nacionalidade")$
sendKeysToElement(list("PORTUGUESA"))
# Find the button "Pesquisar" and click it
remote_driver$
findElement(using = 'name', value = "Reset2")$
clickElement()Make an example
Find the button “Ver Mais” and click it:
library(RSelenium)
link <- "http://www.inci.org.br/acervodigital/livros.php"
# Automatically go the website
driver <- rsDriver(browser = c("firefox"))
remote_driver <- driver[["client"]]
remote_driver$navigate(link)
# Fill the nationality field and click on "Validate"
remote_driver$
findElement(using = "id", value = "nacionalidade")$
sendKeysToElement(list("PORTUGUESA"))
# Find the button "Pesquisar" and click it
remote_driver$
findElement(using = 'name', value = "Reset2")$
clickElement()
# Find the button "Ver Mais" and click it
remote_driver$
findElement(using = 'id', value = "link_ver_detalhe")$
clickElement()Make an example
Get the HTML that is displayed:
library(RSelenium)
link <- "http://www.inci.org.br/acervodigital/livros.php"
# Automatically go the website
driver <- rsDriver(browser = c("firefox"))
remote_driver <- driver[["client"]]
remote_driver$navigate(link)
# Fill the nationality field and click on "Validate"
remote_driver$
findElement(using = "id", value = "nacionalidade")$
sendKeysToElement(list("PORTUGUESA"))
# Find the button "Pesquisar" and click it
remote_driver$
findElement(using = 'name', value = "Reset2")$
clickElement()
# Find the button "Ver Mais" and click it
remote_driver$
findElement(using = 'id', value = "link_ver_detalhe")$
clickElement()
# Get the HTML that is displayed in the modal
x <- remote_driver$getPageSource()Make an example
Exit the modal by pressing “Escape”:
library(RSelenium)
link <- "http://www.inci.org.br/acervodigital/livros.php"
# Automatically go the website
driver <- rsDriver(browser = c("firefox"))
remote_driver <- driver[["client"]]
remote_driver$navigate(link)
# Fill the nationality field and click on "Validate"
remote_driver$
findElement(using = "id", value = "nacionalidade")$
sendKeysToElement(list("PORTUGUESA"))
# Find the button "Pesquisar" and click it
remote_driver$
findElement(using = 'name', value = "Reset2")$
clickElement()
# Find the button "Ver Mais" and click it
remote_driver$
findElement(using = 'id', value = "link_ver_detalhe")$
clickElement()
# Get the HTML that is displayed in the modal
x <- remote_driver$getPageSource()
# Exit the modal by pressing "Escape"
remote_driver$
findElement(using = "xpath", value = "/html/body")$
sendKeysToElement(list(key = "escape"))Problem
We got the content of the first modal, that’s great!
Now we just need to replicate this for the other modals of the page.
How can we distinguish one button “Ver Mais” from another?
Problem
To find the button “Ver Mais”, we used the following code:
But all buttons share the same id, so this code only selects the first button, not the others.
Solution
Use findElements() (and not findElement()).
This returns a list of elements, and we can then apply some function on each of them in a loop:
Loop through modals
Now that we have a way to open each modal, we can make a loop to get the HTML for each one:
for (i in seq_along(buttons)) {
# open the modal
buttons[[i]]$clickElement()
Sys.sleep(0.5)
# get the HTML and save it
tmp <- remote_driver$getPageSource()[[1]]
write(tmp, file = paste0("data/modals/modal-", i, ".html"))
# quit the modal (by pressing "Escape")
remote_driver$
findElement(using = "xpath", value = "/html/body")$
sendKeysToElement(list(key = "escape"))
}Generalize for each page
Find the button to go to the next page:
Nested loops
We know how to:
- open the website
- search for the right inputs
- open each modal and get its content
- go to the next page
Next step: compile all of this and make nested loops!
How many pages? 2348 (but just put 2-3 to avoid too many requests)
Pseudo-code:
How many pages? 2348 (but just put 2-3 to avoid too many requests)
Pseudo-code:
for (page_index in 1:3) {
# Find all buttons "Ver Mais" on the page
buttons <- remote_driver$
findElements(using = 'id', value = "link_ver_detalhe")
for (modal_index in seq_along(buttons)) {
# open modal
# get HTML and save it in an external file
# leave modal
}
# Once all modals of a page have been scraped, go to the next page
# (except if we're on the last page)
}How many pages? 2348 (but just put 2-3 to avoid too many requests)
Make the “modal loop”:
for (page_index in 1:3) {
# Find all buttons "Ver Mais" on the page
buttons <- remote_driver$
findElements(using = 'id', value = "link_ver_detalhe")
for (modal_index in seq_along(buttons)) {
# open modal
buttons[[modal_index]]$clickElement()
# Get the HTML and save it
tmp <- remote_driver$getPageSource()[[1]]
write(tmp, file = paste0("data/modals/modal-", modal_index, ".html"))
# Leave the modal
remote_driver$
findElement(using = "xpath", value = "/html/body")$
sendKeysToElement(list(key = "escape"))
}
# Once all modals of a page have been scraped, go to the next page
# (except if we're on the last page)
}How many pages? 2348 (but just put 2-3 to avoid too many requests)
Make the “page loop”:
for (page_index in 1:3) {
# Find all buttons "Ver Mais" on the page
buttons <- remote_driver$
findElements(using = 'id', value = "link_ver_detalhe")
for (modal_index in seq_along(buttons)) {
# open modal
buttons[[modal_index]]$clickElement()
# Get the HTML and save it
tmp <- remote_driver$getPageSource()[[1]]
write(tmp, file = paste0("data/modals/page-", page_index,
"-modal-", modal_index, ".html"))
# Leave the modal
remote_driver$
findElement(using = "xpath", value = "/html/body")$
sendKeysToElement(list(key = "escape"))
}
# When we got all modals of one page, go to the next page (except if
# we're on the last one)
if (page_index != 2348) {
remote_driver$
findElement("css", "#paginacao > div.btn:nth-child(4)")$
clickElement()
}
}
Great, let’s run everything!
Not so fast
Error handling
1. Catching errors
Catching errors
The default behavior of errors is to stop the script, which leads to this kind of situation:
- 7pm - “great, I can just run the code during the night and go home”
- 7:02pm - error in the code
- 8am - “Fu@?!”
need to handle errors with tryCatch()
Catching errors
tryCatch
try to run an expression
catch the potential warnings/errors
Catching errors
Example: try to compute log("a").
What if I want to return NA instead of an error?
Catching errors
Catching errors
Catching errors
tryCatch(
# try to evaluate the expression
{
log("a")
},
# what happens if there's a warning?
warning = function(w) {
print("There was a warning. Here's the message:")
print(w)
},
# what happens if there's an error?
error = function(e) {
print("There was an error. Returning `NA`.")
return(NA)
}
)[1] "There was an error. Returning `NA`."[1] NAExample with a loop
Create a fake loop that goes from i = 1:10 and creates a list containing i*2. Let’s say that there’s an error when i = 3:
Example with a loop
Create a fake loop that goes from i = 1:10 and creates a list containing i*2. Let’s say that there’s an error when i = 3:
Example with a loop
We don’t have values for i >= 3 because there was an error that stopped the loop.
Catching the error
Now, let’s catch the error to avoid breaking the loop:
Catching the error
[1] "i = 1. So far so good."
[1] "i = 2. So far so good."
[1] "Error for i = 3. `x[[3]]` will be NULL."
[1] "i = 3. So far so good."
[1] "i = 4. So far so good."
[1] "i = 5. So far so good."
[1] "i = 6. So far so good."
[1] "i = 7. So far so good."
[1] "i = 8. So far so good."
[1] "i = 9. So far so good."
[1] "i = 10. So far so good."[[1]]
[1] 2
[[2]]
[1] 4
[[3]]
NULL
[[4]]
[1] 8
[[5]]
[1] 10
[[6]]
[1] 12
[[7]]
[1] 14
[[8]]
[1] 16
[[9]]
[1] 18
[[10]]
[1] 20Using tryCatch in our loop
We can now catch errors when we try to get the content of each modal:
tryCatch(
{
# open modal
buttons[[modal_index]]$clickElement()
Sys.sleep(1.5)
# Get the HTML and save it
tmp <- remote_driver$getPageSource()[[1]]
write(tmp, file = paste0("data/modals/page-", page_index, "-modal-", modal_index, ".html"))
# Leave the modal
body <- remote_driver$findElement(using = "xpath", value = "/html/body")
body$sendKeysToElement(list(key = "escape"))
message(paste(" Scraped modal", modal_index))
},
error = function(e) {
message(paste(" Failed to scrape modal", modal_index))
message(paste(" The error was ", e))
next
}
)2. Loading times
Loading times
There are a few places where we need to wait a bit:
- after clicking on “Pesquisar”
- after clicking on “Ver Mais”
- when we go to the next page
We must put some pauses between RSelenium actions. Otherwise it will error, e.g. if we try to click on a button that isn’t loaded on the page yet.
one solution is to use Sys.sleep()
Loading times
for (page_index in 1:2348) {
# Find all buttons "Ver Mais" on the page
buttons <- remote_driver$
findElements(using = 'id', value = "link_ver_detalhe")
for (modal_index in seq_along(buttons)) {
# open modal
buttons[[modal_index]]$clickElement()
Sys.sleep(0.5)
# Get the HTML and save it
tmp <- remote_driver$getPageSource()[[1]]
write(tmp, file = paste0("data/modals/page-", page_index,
"-modal-", modal_index, ".html"))
# Leave the modal
remote_driver$
findElement(using = "xpath", value = "/html/body")$
sendKeysToElement(list(key = "escape"))
Sys.sleep(0.5)
}
# When we got all modals of one page, go to the next page (except if
# we're on the last one)
if (page_index != 2348) {
remote_driver$
findElement("css", "#paginacao > div.btn:nth-child(4)")$
clickElement()
Sys.sleep(3)
}
}Loading times
However, using Sys.sleep() is not perfect because we put arbitrary timing, e.g. 5 seconds.
Problem: what if the Internet connection is so bad that the loading takes 10 seconds?
we need a more robust solution using tryCatch()
Loading times
What we want is to check whether the loading is over, i.e whether the buttons we want to click can be found on the page.
We can use a while() loop to check this.
Loading times
Quick reminder:
ifcondition: perform the inside only if the condition is true
Loading times
In our case, we want to check whether we can find the buttons “Ver Mais”.
Are the buttons loaded?
- if no, wait 0.5 seconds (or whatever duration you want), and try again;
- if yes, go to the next step
Do this 20 times max
Loading times
# Try to find the buttons "Ver Mais" all_buttons_loaded <- FALSE iterations <- 0 while(!all_buttons_loaded & iterations < 20) { tryCatch( { test <- remote_driver$ findElements(using = 'id', value = "link_ver_detalhe") # If the buttons are found, update our condition to quit the loop if (inherits(test, "list") && length(test) > 0) { all_buttons_loaded <<- TRUE } }, error = function(e) { iterations <<- iterations + 1 Sys.sleep(0.5) } ) }# Try to find the buttons "Ver Mais" all_buttons_loaded <- FALSE iterations <- 0 while(!all_buttons_loaded & iterations < 20) { tryCatch( { test <- remote_driver$ findElements(using = 'id', value = "link_ver_detalhe") # If the buttons are found, update our condition to quit the loop if (inherits(test, "list") && length(test) > 0) { all_buttons_loaded <<- TRUE } }, error = function(e) { iterations <<- iterations + 1 Sys.sleep(0.5) } ) }# Try to find the buttons "Ver Mais" all_buttons_loaded <- FALSE iterations <- 0 while(!all_buttons_loaded & iterations < 20) { tryCatch( { test <- remote_driver$ findElements(using = 'id', value = "link_ver_detalhe") # If the buttons are found, update our condition to quit the loop if (inherits(test, "list") && length(test) > 0) { all_buttons_loaded <<- TRUE } }, error = function(e) { iterations <<- iterations + 1 Sys.sleep(0.5) } ) }
This loop will run until the buttons can be found or until we reach 20 iterations.
Loading times
for (page_index in 1:2348) {
# Try to find the buttons "Ver Mais"
all_buttons_loaded <- FALSE
iterations <- 0
while(!all_buttons_loaded & iterations < 20) {
tryCatch(
{
test <- remote_driver$
findElements(using = 'id', value = "link_ver_detalhe")
if (inherits(test, "list") && length(test) > 0) {
all_buttons_loaded <<- TRUE
}
},
error = function(e) {
iterations <<- iterations + 1
Sys.sleep(0.5)
}
)
}
if (!all_buttons_loaded & iterations == 20) {
next
}
buttons <- remote_driver$
findElements(using = 'id', value = "link_ver_detalhe")
for (modal_index in seq_along(buttons)) {
# open modal
buttons[[modal_index]]$clickElement()
Sys.sleep(1.5)
# Get the HTML and save it
tmp <- remote_driver$getPageSource()[[1]]
write(tmp, file = paste0("data/modals/page-", page_index, "-modal-", modal_index, ".html"))
# Leave the modal
remote_driver$
findElement(using = "xpath", value = "/html/body")$
sendKeysToElement(list(key = "escape"))
Sys.sleep(1.5)
}
# When we got all modals of one page, go to the next page (except if
# we're on the last one)
if (page_index != 2348) {
remote_driver$
findElement("css", "#paginacao > div.btn:nth-child(4)")$
clickElement()
}
}3. Display and save information
Display and save information
Webscraping takes time.
It is important to show and save information on how the webscraping is going so that we know where it went wrong for debugging.
In our case:
- show which page is being scraped;
- show which modal of this page is being scraped;
- show the status of this scraping (success/failure).
Display information
Use message() at several places in the loop to display information:
for (page_index in 1:2348) {
message(paste("Start scraping of page", page_index))
for (modal_index in buttons) {
# open modal
# get HTML and save it in an external file
# leave modal
message(paste(" Scraped modal", modal_index))
}
# Once all modals of a page have been scraped, go to the next page (except
# if we're on the last page)
message(paste("Finished scraping of page", page_index))
}Save information
Problem: what if the R session crashes?
We lose all messages!
Solution: show these messages and save them in an external file at the same time.
Save information
Example using the package logger (there are also logging, futile.logger, etc.):
# save calls to message() in an external file
log_appender(appender_file("data/modals/00_logfile"))
log_messages()
for (page_index in 1:2348) {
message(paste("Start scraping of page", page_index))
for (modal_index in buttons) {
# open modal
# get HTML and save it in an external file
# leave modal
message(paste(" Scraped modal", modal_index))
}
# Once all modals of a page have been scraped, go to the next page (except
# if we're on the last page)
message(paste("Finished scraping of page", page_index))
}Save information
What does the output look like?
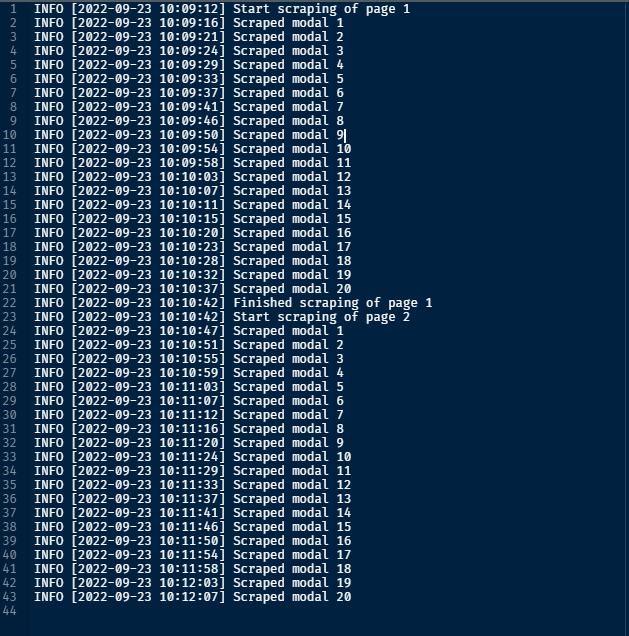
Final loop
for (page_index in 1:3) {
message(paste("Start scraping of page", page_index))
# Try to find the buttons "Ver Mais"
all_buttons_loaded <- FALSE
iterations <- 0
while(!all_buttons_loaded & iterations < 20) {
tryCatch(
{
test <- remote_driver$
findElements(using = 'id', value = "link_ver_detalhe")
if (inherits(test, "list") && length(test) > 0) {
all_buttons_loaded <<- TRUE
}
},
error = function(e) {
iterations <<- iterations + 1
Sys.sleep(0.5)
}
)
}
if (!all_buttons_loaded & iterations == 20) {
message(paste0("Couldn't find buttons on page ", page_index, ". Skipping."))
next
}
buttons <- remote_driver$
findElements(using = 'id', value = "link_ver_detalhe")
for (modal_index in seq_along(buttons)) {
tryCatch(
{
# open modal
buttons[[modal_index]]$clickElement()
Sys.sleep(1.5)
# Get the HTML and save it
tmp <- remote_driver$getPageSource()[[1]]
write(tmp, file = paste0("data/modals/page-", page_index, "-modal-", modal_index, ".html"))
# Leave the modal
body <- remote_driver$findElement(using = "xpath", value = "/html/body")
body$sendKeysToElement(list(key = "escape"))
message(paste(" Scraped modal", modal_index))
},
error = function(e) {
message(paste(" Failed to scrape modal", modal_index))
message(paste(" The error was ", e))
next
}
)
Sys.sleep(1.5)
}
# When we got all modals of one page, go to the next page (except if
# we're on the last one)
if (page_index != 2348) {
remote_driver$
findElement("css", "#paginacao > div.btn:nth-child(4)")$
clickElement()
}
message(paste("Finished scraping of page", page_index))
# Wait a bit for page loading
Sys.sleep(3)
}Now what?
If everything went well, we now have a bunch of .html files in data/modals.
To clean them, we don’t need RSelenium or an internet connection. These are just text files, they are not “tied” to the website anymore.
It is also useful to keep them for reproducibility (same as when you keep the raw datasets in your project).
Make a function to clean the HTML. It returns a list containing a dataframe with the personal info, and a dataframe with the “network” of the individual.
extract_information <- function(raw_html) {
# Extract the table "Registros relacionados"
content <- raw_html %>%
html_nodes("#detalhe_conteudo") %>%
html_table() %>%
purrr::pluck(1)
relacionados <- content[16:nrow(content),] %>%
mutate(
across(
.cols = everything(),
.fns = ~ {ifelse(.x == "", NA, .x)}
)
)
colnames(relacionados) <- c("Livro", "Pagina", "Familia", "Chegada",
"Sobrenome", "Nome", "Idade", "Sexo",
"Parentesco", "Nacionalidade",
"Vapor", "Est.Civil", "Religiao")
# Extract text information from "registro de matricula" and create a
# dataframe from it
name_items <- raw_html %>%
html_elements(xpath = '//*[@id="detalhe_conteudo"]/table[1]/tbody/tr/td/strong') %>%
html_text2() %>%
gsub("\\n", "", .) %>%
strsplit(split = "\\t") %>%
unlist()
value_items <- raw_html %>%
html_elements(xpath = '//*[@id="detalhe_conteudo"]/table[1]/tbody/tr/td/div') %>%
html_text2()
registro <- data.frame() %>%
rbind(value_items) %>%
as_tibble()
colnames(registro) <- name_items
return(
list(
main = registro,
related = relacionados
)
)
}Apply this function to all files:
library(tidyverse)
library(rvest)
# Get all paths to the html files
list_html_files <- list.files("data/modals", pattern = "page",
full.names = TRUE)
# Apply the previous function to each of those file
list_out <- lapply(list_html_files, function(x) {
read_html(x) |>
extract_information()
})
# Aggregate the results in two (single) datasets
main <- data.table::rbindlist(purrr::map(list_out, 1)) |>
as_tibble()
relations <- data.table::rbindlist(purrr::map(list_out, 2)) |>
as_tibble()Summary
Seleniumin general is a very useful tool but should be used as a last resort:
- APIs, packages
- static webscraping
- custom
POSTrequests
- In my (limited) experience:
- 1/4 of the time is spent on making a small example work;
- 1/4 of the time is spent on generalising this example (loops, etc.)
- 1/2 of the time is spent on debugging.
Catching errors and recording the scraping process IS important.
Parallelization
Use parallelization to open several browsers at the same time and scrape the data faster.
I never tested this, and there could be some issues (browser crashes, etc.)
If you want to explore it:
article by Appsilon (at the end)
Ethics
Pay attention to a website’s Terms of Use/Service.
Some websites explicitely say that you are not allowed to programmatically access their resources.
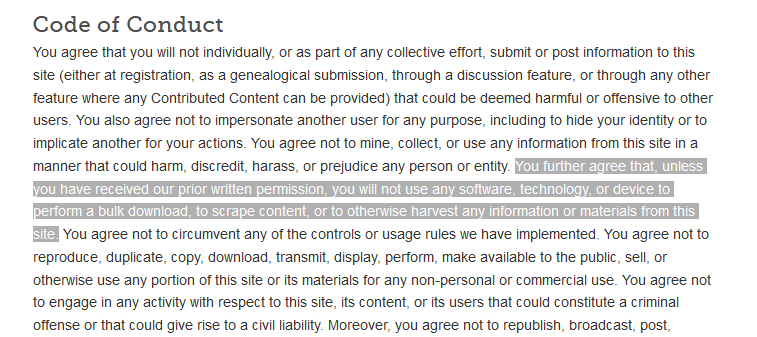
Ethics
Be respectful: make the scraping slow enough not to overload the server.
Not every website can handle tens of thousands of requests very quickly.
Tip
For static webscraping, check out the package polite.
Thanks!
Source code for slides and exercises:
https://github.com/etiennebacher/webscraping-teaching
Comments, typos, etc.:
https://github.com/etiennebacher/webscraping-teaching/issues
Good resources
Article from Appsilon:
https://appsilon.com/webscraping-dynamic-websites-with-r/
Article from Ivan Millanes:
https://ivanmillanes.netlify.app/post/2020-06-30-webscraping-with-rselenium-and-rvest/
Appendix
Appendix
For reference, here’s the code to extract the list of contributors:
library(rvest)
html <- read_html("contributors.html")
bullet_points <- html %>%
html_elements(css = "div.col-xs-12 > ul > li") %>%
html_text()
blockquote <- html %>%
html_elements(css = "div.col-xs-12.col-sm-7 > blockquote") %>%
html_text() %>%
strsplit(., split = ", ")
blockquote <- blockquote[[1]] %>%
gsub("\\r|\\n|\\.|and", "", .)
others <- html %>%
html_elements(xpath = "/html/body/div/div[1]/div[2]/p[5]") %>%
html_text() %>%
strsplit(., split = ", ")
others <- others[[1]] %>%
gsub("\\r|\\n|\\.|and", "", .)
all_contributors <- c(bullet_points, blockquote, others)Appendix
[1] "Douglas Bates" "John Chambers" "Peter Dalgaard"
[4] "Robert Gentleman" "Kurt Hornik" "Ross Ihaka"
[7] "Tomas Kalibera" "Michael Lawrence" "Friedrich Leisch"
[10] "Uwe Ligges" "Thomas Lumley" "Martin Maechler"
[13] "Sebastian Meyer" "Paul Murrell" "Martyn Plummer"
[16] "Brian Ripley" "Deepayan Sarkar" "Duncan Temple Lang"
[19] "Luke Tierney" "Simon Urbanek" "Valerio Aimale"
[22] "Suharto Anggono" "Thomas Baier" "Gabe Becker"
[25] "Henrik Bengtsson" "Roger Biv" "Ben Bolker"
[28] "David Brahm" "Göran Broström" "Patrick Burns"
[31] "Vince Carey" "Saikat DebRoy" "Matt Dowle"
[34] "Brian D’Urso" "Lyndon Drake" "Dirk Eddelbuettel"
[37] "Claus Ekstrom" "Sebastian Fischmeister" "John Fox"
[40] "Paul Gilbert" "Yu Gong" "Gabor Grothendieck"
[43] "Frank E Harrell Jr" "Peter M Haverty" "Torsten Hothorn"
[46] "Robert King" "Kjetil Kjernsmo" "Roger Koenker"
[49] "Philippe Lambert" "Jan de Leeuw" "Jim Lindsey"
[52] "Patrick Lindsey" "Catherine Loader" "Gordon Maclean"
[55] "Arni Magnusson" "John Maindonald" "David Meyer"
[58] "Ei-ji Nakama" "Jens Oehlschägel" "Steve Oncley"
[61] "Richard O’Keefe" "Hubert Palme" "Roger D Peng"
[64] "José C Pinheiro" "Tony Plate" "Anthony Rossini"
[67] "Jonathan Rougier" "Petr Savicky" "Günther Sawitzki"
[70] "Marc Schwartz" "Arun Srinivasan" "Detlef Steuer"
[73] "Bill Simpson" "Gordon Smyth" "Adrian Trapletti"
[76] "Terry Therneau" "Rolf Turner" "Bill Venables"
[79] "Gregory R Warnes" "Andreas Weingessel" "Morten Welinder"
[82] "James Wettenhall" "Simon Wood" " Achim Zeileis"
[85] "J D Beasley" "David J Best" "Richard Brent"
[88] "Kevin Buhr" "Michael A Covington" "Bill Clevel"
[91] "Robert Clevel," "G W Cran" "C G Ding"
[94] "Ulrich Drepper" "Paul Eggert" "J O Evans"
[97] "David M Gay" "H Frick" "G W Hill"
[100] "Richard H Jones" "Eric Grosse" "Shelby Haberman"
[103] "Bruno Haible" "John Hartigan" "Andrew Harvey"
[106] "Trevor Hastie" "Min Long Lam" "George Marsaglia"
[109] "K J Martin" "Gordon Matzigkeit" "C R Mckenzie"
[112] "Jean McRae" "Cyrus Mehta" "Fionn Murtagh"
[115] "John C Nash" "Finbarr O’Sullivan" "R E Odeh"
[118] "William Patefield" "Nitin Patel" "Alan Richardson"
[121] "D E Roberts" "Patrick Royston" "Russell Lenth"
[124] "Ming-Jen Shyu" "Richard C Singleton" "S G Springer"
[127] "Supoj Sutanthavibul" "Irma Terpenning" "G E Thomas"
[130] "Rob Tibshirani" "Wai Wan Tsang" "Berwin Turlach"
[133] "Gary V Vaughan" "Michael Wichura" "Jingbo Wang"
[136] "M A Wong" Appendix
Bonus: get the data from each modal on the museum website by performing the POST request yourself.
Go to the tab “Network” in the developer console, and then click on one of the “Ver Mais” button to display the modal.
Appendix
Clicking on this button triggers two POST requests:
- one for the individual information;
- one for the “network” of the individual.
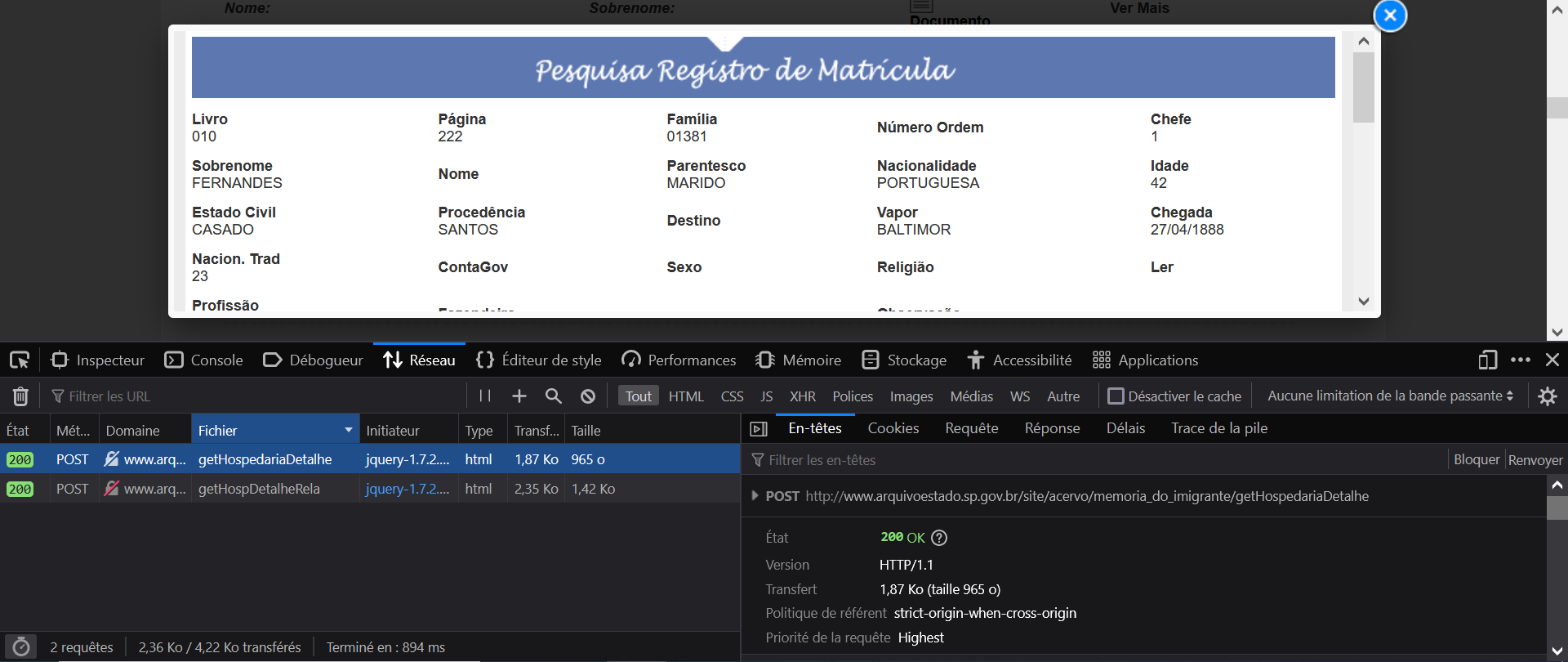
Appendix
Clicking on one of the POST requests displays important information:
- the request, what we send to the server;
- the response, what the server sends back to us.
The request contains specific parameters needed to tell the server which data we need.
Appendix
Let’s rebuild this POST request from R using the package httr.
Appendix
Extract the data from the server response:
library(httr)
library(xml2)
library(jsonlite)
# make the POST request with the parameters needed
x <- POST(
"http://www.arquivoestado.sp.gov.br/site/acervo/memoria_do_imigrante/getHospedariaDetalhe",
body = list(
id = "92276"
),
encode = "multipart"
)
# convert output to a list
out <- as_list(content(x))
# convert output to a dataframe
fromJSON(unlist(out))$dadosYour turn
Do the same thing with the second POST request, which has 3 parameters instead of one.
Session information
─ Session info ───────────────────────────────────────────────────────────────
setting value
version R version 4.2.2 (2022-10-31 ucrt)
os Windows 10 x64 (build 19044)
system x86_64, mingw32
ui RTerm
language (EN)
collate English_Europe.utf8
ctype English_Europe.utf8
tz Europe/Paris
date 2023-02-22
pandoc 3.1 @ C:/Users/etienne/AppData/Local/Pandoc/ (via rmarkdown)
─ Packages ───────────────────────────────────────────────────────────────────
package * version date (UTC) lib source
cli 3.6.0 2023-01-09 [1] CRAN (R 4.2.2)
digest 0.6.31 2022-12-11 [1] CRAN (R 4.2.2)
evaluate 0.20 2023-01-17 [1] CRAN (R 4.2.2)
fastmap 1.1.0 2021-01-25 [1] CRAN (R 4.2.0)
glue 1.6.2 2022-02-24 [1] CRAN (R 4.2.0)
htmltools 0.5.4 2022-12-07 [1] CRAN (R 4.2.2)
httr 1.4.4 2022-08-17 [1] CRAN (R 4.2.1)
jsonlite 1.8.4 2022-12-06 [1] CRAN (R 4.2.2)
knitr 1.42 2023-01-25 [1] CRAN (R 4.2.2)
lifecycle 1.0.3 2022-10-07 [1] CRAN (R 4.2.1)
magrittr 2.0.3 2022-03-30 [1] CRAN (R 4.2.0)
R6 2.5.1 2021-08-19 [1] CRAN (R 4.2.0)
rlang 1.0.6.9000 2023-02-20 [1] Github (r-lib/rlang@394204f)
rmarkdown 2.20 2023-01-19 [1] CRAN (R 4.2.2)
rstudioapi 0.14 2022-08-22 [1] CRAN (R 4.2.1)
rvest * 1.0.3 2022-08-19 [1] CRAN (R 4.2.1)
selectr 0.4-2 2019-11-20 [1] CRAN (R 4.2.0)
sessioninfo 1.2.2 2021-12-06 [1] CRAN (R 4.2.0)
stringi 1.7.12 2023-01-11 [1] CRAN (R 4.2.2)
stringr 1.5.0 2022-12-02 [1] CRAN (R 4.2.2)
vctrs 0.5.2.9000 2023-02-20 [1] Github (r-lib/vctrs@303b5dd)
xfun 0.37 2023-01-31 [1] CRAN (R 4.2.2)
xml2 1.3.3 2021-11-30 [1] CRAN (R 4.2.0)
yaml 2.3.7 2023-01-23 [1] CRAN (R 4.2.2)
[1] C:/Users/etienne/AppData/Local/R/win-library/4.2
[2] C:/R/library
──────────────────────────────────────────────────────────────────────────────